Traduction de l’article The 5 Types Of React Application State
NDT: J’ai pris parti de ne pas traduire les termes suivants: store, state et reducer car nous les utilisons couramment dans nos métiers de développeur et je trouve que cela nui à la compréhension du texte de les traduire en français.
Voici l’article, bonne lecture 😁 :
Je ne sais pas pour vous, mais quand j’ai commencé à écrire des applications React, j’ai eu des difficultés à décider où mon state devrait aller. Peu import comment je réarrangeais les appels à setState, j’avais le sentiment que quelque chose n’était jamais vraiment correct.
Et peut-être pour ça que j’étais si excité quand j’ai trouvé Redux. Redux m’a donné une place unique pour y mettre tout mon state. Ce qui paraissait merveilleux en théorie.
Mais j’ai ensuite réalisé qu’avoir un seul endroit pour y mettre les choses n’est pas nécessairement facile à comprendre.
Il s’est avéré que j’avais besoin de plus que d’un endroit où ranger les choses. J’ai aussi besoin d’un système pour les mettre à la bonne place.
Pour moi, ce système est venu en séparant mon state en 5 catégories. Cela à modifié le problème de décider “comment cette partie du state est reliée à tous les autres state”, en problème pour décider “quel type de state c’est”. Et il s’avère que c’est beaucoup plus facile.
Donc voilà l’affaire. Les applications React ont cinq types de state. Chaque type de state à un nombre de règles qu’il suit. Il interagit de manière bien définie avec les autres types de state, aussi longtemps qu’il suit les règles. Et sur la base de ces règles, vous verrez qu’il existe une manière de stocker le state qui à un sens.
Alors sans plus tarder, vos cinq types de state sont :
- les données
- la communication
- le contrôle
- la session
- l’emplacement
Et dans ces cinq, les “données” est celui qui à vraiment besoin d’un meilleur nom. C’est aussi le plus facile à expliquer. Donc, creusons.
Les Données
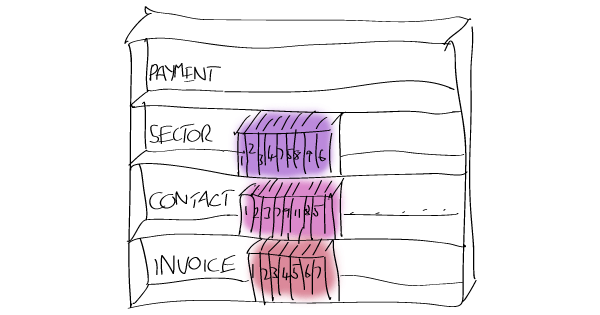
Le state de type Données couvre les informations que votre application enregistre temporairement sur le vaste monde. C’est-à-dire qu’il couvre les données de votre service.
Maintenant, disons que vous construisez quelque chose de tendance et cool comme une application de facture. Le state de type “Données” pour votre application inclura des éléments reçus du serveur comme les factures, les contacts, les reçus… Et, comme toutes vos données proviendront du monde extérieur, il est probable qu’elles viendront avec une sorte d’identifiant que vous utiliserez pour les requêter :
GET la route /invoice avec ?id=happiness, ou quelque chose.
En fait, je vais consigner ça comme La règle du state de Données :
Chaque donnée reçue a un type et un sélecteur qui spécifie exactement quelles données ont été reçues.
Cela facilite la conception d’un store Redux pour vos données; au minimum, il va inclure un moyen de mapper un type et un id sur un objet reçu. Il inclura aussi des actions pour mettre à jour le store avec les objets reçus.
Et c’est fantastique, car maintenant nous avons un store de Données qui peut être accessible de n’importe où dans l’application en utilisant connect. En outre, tant que vos données respectent la règle du state pour le type “Donnée”, vous pouvez pimenter les choses avec des index et des composants d’ordre supérieur.
Bien sûr, les données n’apparaissent pas comme par magie dans une application. Nous avons besoin de les requêter, et puis attendre jusqu’à ce que la requête réussisse ou échoue. Et c’est là que le state “communication” arrive.
Le state Communication
Ce type de state couvre les informations apparemment simples, mais quelque peu épineuses qui représentent des choses comme les animations de chargement et les messages d’erreur. Il couvre également le state que vous n’avez peut-être pas réalisé avoir introduit dans votre application quand vous avez exécuté une fonction de rappel à une requête HTTP.
Mais l’explication ci-dessus est assez complexe. Pour simplifier les choses, oublions ce que le state Communication fait, et pensons plutôt de quoi il s’agit. En fait, La règle du state Communication couvre ceci :
Le _state_ Communiquation est le statut de toutes requêtes non finies adressé à d’autres services.
Cela signifie que tous les éléments suivants sont un state Communication :
- Le type/sélecteur de toutes les données que vous attendez recevoir
- Le type, le sélecteur et le changement attendu de toutes les opérations que vous avez demandé sur les données
- Les messages d’erreurs pour tout ce qui ne s’est pas passé comme prévu
Définir le state Communication de cette manière à deux avantages majeurs :
- Vous pouvez le stocker avec un simple reducer de Redux qui gère un tableau d’objets de requête
- Vous pouvez maintenant calculer le statut (
retrieving,updating,toutcequiarrive, etc.) de n’importe qu’elle données dans votre store avec une fonction pure de votre state de Données et de Communications. - Énorme. Ce qui veut dire que maintenant, vous n’avez plus jamais à écrire un
setState({ saving: trueorfalse}).
Ainsi, les deux state Communication et Données peuvent être implémentées comme des store indépendants, gérés par Redux. Ils sont tous les deux accessible dans votre application entière en utilisant connect. Je commence à voir un modèle ici, peut-être que tous les state s’intègrent bien dans un certain type de Reducer que toute l’application peut utiliser ? Si seulement c’était aussi simple.
Le state Contrôle
Contrairement aux deux types de state ci-dessus, le state Control ne représente pas l’environnement de l’application. Au lieu de cela, il fait référence à l’état dans lequel l’utilisateur est entré dans l’application. Champs de formulaire, éléments sélectionnés, des choses comme ça.
Des choses comme quoi ? Oui, vous avez peut-être remarqué que les formulaires et les éléments sélectionnés sont des types d’informations complètement différentes. Les éléments sélectionnés prennent probablement la forme d’une simple chaîne de caractères représentant un identifiant, alors que les formulaires peuvent être d’énormes objets imbriqués. Et ça, c’est le truc à propos du state Control, sa forme ne suis pas vraiment de modèle particulier.
Heureusement, il suit un autre type de modèle. Voyez-vous, l’aspect intéressant à propos du state Control est qu’il est généralement spécifique à une vue unique. Ou écran. Ou un composant conteneur. Ce qui nous amène à la Règle du state Contrôle :
Le State Contrôle est un state qui est spécifique à un composant conteneur donné et qui n’est pas stocké dans l’URL de l’écran ou dans l’API History d’HTML5.

Génial, donc nous avons un modèle à utiliser. Maintenant comment nous allons utiliser ce modèle pour écrire un reducer Redux pour nos vues ? Réfléchissez un peu à ce sujet, et une fois que vous avez la réponse, lisez la réponse à la phrase suivante.
Vous ne pouvez pas.
Avez-vous pensé à cela pendant un moment ? Pardon. Mais je pense que c’est un point important à faire connaître. Et Dan Abramov, auteur de Redux, semble le penser aussi :
N’utilisez pas Redux jusqu’à ce que vous ayez des problèmes avec vanilla React.
N’oubliez pas que les state Données et Communication ont besoin d’être disponibles dans l’application entière. Le state Control doit uniquement être disponible pour une vue spécifique. Et cela signifie que setState, disponible dans vanilla React, est parfait.
En fait, j’ai fait abstraction d’un point important, donc laissez-moi-le préciser un peu mieux :
Vous n’avez pas besoin d’utiliser la même méthode pour enregistrer chaque type de state. Sérieusement.
Vous avez un state qui a une forme prévisible et qui a besoin d’être disponible n’importe où dans votre application ? Utilisez Redux. Qu’en est-il d’un state avec une forme imprévisible qui se limite à une seule vue ? Utilisez setState. Vous avez peut-être un state qui a besoin d’être disponible de partout, mais qui à une forme imprévisible ? Heu…
Le state Session
Lorsque vous avez une information qui a besoin d’être disponible au niveau général de l’application, mais que sa forme est bien moins définie que la planification de votre projet, il s’agit probablement d’un state Session.
En d’autres termes, nous avons la première règle du state Session :
Le state Session contient des informations sur l’utilisateur qui utilise actuellement votre application.
Cela inclut les éléments évidents comme leur identifiant d’utilisateur, les permissions, etc. Mais il peut aussi inclure les préférences de l’utilisateur qui gère comment l’application fonctionne pour lui.
Maintenant, une chose à propos du state Session est que certaines parties peuvent être assez similaires au state Control. Par exemple, vous pouvez avoir une partie du state Session qui représente … exactement la même chose. Mais je vous promets qu’il y a une différence. Et vous pouvez probablement l’imaginer vous-même avec la deuxième règle du state Session :
Le state Session est seulement lu quand le composant est monté.
Bien entendu, cela veut dire que la version du state Session de votre vue en construction est une copie du state Control. Bien sûr, vous pouvez écrire dans la session quand vous le voulez. Mais il est seulement lu pour initialiser la vue. Ou pour le dire autrement : le state Session peut être utilisé pour sauver les préférences.
Ok, cool. Donc comment le state Session est-il stocké ? Comme ceci :
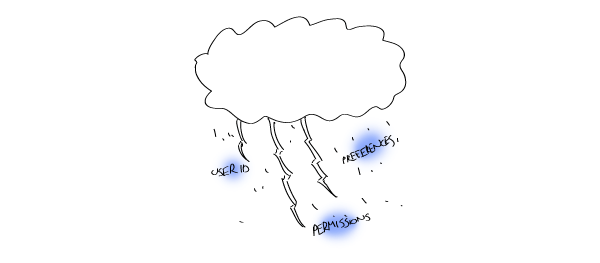
Le state Session tombe d’en haut. Dans le monde de React, cela signifie que c’est juste probablement un vieil objet simple qui à trouvé son chemin dans le contexte de votre composant. Vous voulez sûrement un moyen pour être sûr qu’il ne disparaîtra pas entre deux chargements de page, mais je suis sûr que vous pouvez comprendre cela. Mais avant ça, parlons du plus méchant, féroce state entre tous.
Le state Localisation
Qu’est-ce qui compte comme localisation ? Intuitivement, je dirai «tout ce qui vous permet de donner à quelqu’un une direction concrète où aller». Mais une explication délicate comme celle-là ne nous emmènera pas loin. Donc, essayons quelque chose de concret :
Le state Localisation est le désordre UTF-8 qui apparaît dans votre barre d’URL.
Cette définition comporte un certain nombre d’éléments:
- Ce désordre représente définitivement le state de votre application
- Le partager entre utilisateurs revient à donner des informations
- Le L dans URL signifie localisateur
Mais aussi géniale que soit cette définition, elle n’est pas vraiment complète. Pour commencer, cela ne prend pas en compte le fait que vous pouvez donner aux gens des indications sur des parties de votre application qui n’ont pas d’URL unique. En outre, l’API d’historique HTML5 vous permet de stocker le store séparément de l’URL. Pour ce faire, vous appelez une méthode appelée pushState.
Pour être honnête, je n’ai pas vraiment réussi à établir une définition précise du state Localisation. Donc, j’en donne une pragmatique à la place. Et donc la Règle du state Localisation :
Le state Localisation est une information enregistrée dans l’URL et dans l’objet state de l’API History d’HTML5.
Habilement, cette définition couvre à la fois le type d’information qui est enregistrée, et sa méthode de stockage. Malheureusement, cela ne nous aide pas avec la structure. À la place, elle nous force à stocker l’une des plus importantes pièces du state dans toute l’application comme une satanée chaîne de caractères.
Et il va sans dire qu’aucun webmaster compétent ne construira une importante application Web avec un routage basé sur window.location.hash.indexOf. Mais l’une des choses marrantes à propos des URL est que, bien qu’elle soit stockée comme des chaînes de caractères, elles ne représentent pas des chaînes de caractères. Elle représente en réalité une hiérarchie. Et cela se superpose à la hiérarchie des composants de votre application.
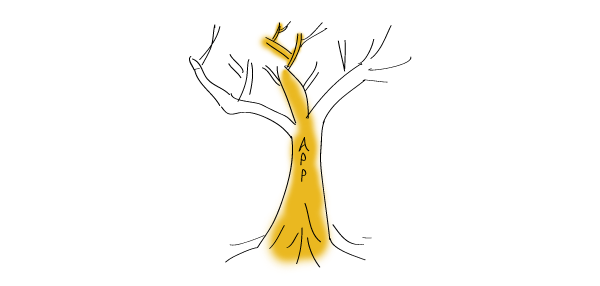
En fait, en combinant la hiérarchie enregistrée dans les URL avec la possibilité d’enregistrer un emplacement supplémentaire avec pushState, vous pouvez créer un arbre de localisation qui cartographie (espérons proprement) un sous-ensemble de l’arbre de composant de votre application. Autrement dit, votre state Localisation finit par être un ensemble d’indicateurs qui active et désactive les branches de votre application. Simple, non ?
Ça le serait, is il n’y avait pas d’effets secondaires.
Effets secondaires
Sur nos cinq types de state, quatre d’entre eux sont pour la plupart liés à leur propre buisness. Modifier les Data, Les state Communication, Contrôle et Session ne causent généralement pas de modification d’autres types de state.
Le state Location est d’un type complètement différent. Chaque foi qu’il change, vous constaterez qu’un autre state change aussi :
- Changer la Localisation monte les composants du conteneur, entraînant le changement du state Contrôle
- Changer la Localisation créée des requêtes HTTP qui provoque le changement du state Communication, avant de modifier également le state Data
- Changer la Localisation peut même entraîner un changement de Localisation ! C’est ce que font les redirections.
Alors voici la chose à propos de la bonne structuration de votre state : vous réalisez soudainement comment les effets secondaires non contrôlés sont douloureux.
Heureusement, ils n’ont pas à rester non contrôlés. C’est à quoi servent les contrôleurs.